Facial Keypoints Detection
A dual-framework deep learning system for detecting 15 facial keypoints (30 x,y coordinates) on 96×96 grayscale images. Implements both a Keras CNN with two-phase training and a PyTorch ResNet with custom NaN-aware loss, achieving a Kaggle RMSE of 2.10 on the Facial Keypoints Detection competition.
The key innovation is the NaN-aware MSE loss function that trains on all 7,049 samples — including the ~5,000 with partial keypoint labels — rather than discarding ~70% of the data. Combined with a 6-stage ResNet architecture (12 residual blocks) and careful learning rate scheduling, this approach significantly outperforms the baseline CNN.

Model Comparison
| Model | Framework | Parameters | Kaggle RMSE | Strategy |
|---|---|---|---|---|
| ResNet | PyTorch | ~4.2M | 2.10 | Adam + StepLR + NaN-aware MSE |
| CNN | TensorFlow/Keras | ~1.5M | 2.55 | Two-phase: Adam → SGD + Huber |
ResNet Architecture
Input (1×96×96 grayscale) ├― Stem: Conv(1→32, 7×7) → BatchNorm → ReLU → MaxPool ├― Stage 1: ResBlock×2 (32 → 32) ├― Stage 2: ResBlock×2 (32 → 64) stride=2 ├― Stage 3: ResBlock×2 (64 → 128) stride=2 ├― Stage 4: ResBlock×2 (128 → 256) stride=2 ├― Stage 5: ResBlock×2 (256 → 512) stride=2 ├― AdaptiveAvgPool2d(1×1) └― Linear(512 → 30) ―――― 15 keypoints × 2 (x, y) ResBlock: x → Conv3×3 → BN → ReLU → Conv3×3 → BN → (+shortcut) → ReLU Shortcut: 1×1 conv when dimensions change
Training Pipeline
Input: 96×96 Grayscale Image (CSV pixel strings) ├― Pixel normalization (0-255 → 0-1) ├― NaN handling: forward-fill (CNN) / mask (ResNet) └― Train/Val split (80/20) CNN (Keras/TensorFlow) ResNet (PyTorch) Conv2D(32→64→128) Stem: Conv(1→32)+BN+Pool Dense(500→500→30) 5 Stages: ResBlock×2 each LeakyReLU + Dropout (32→64→128→256→512) Huber loss AvgPool → Linear(512→30) Adam → SGD (two-phase) NaN-aware MSE + Adam + StepLR └―――――――――――│――――――――――――┌ Output: 30 values (x,y for 15 keypoints) └― Kaggle submission CSV via IdLookupTable
Key Features
- Dual-framework architecture — PyTorch ResNet and Keras CNN sharing data loading, configuration, and prediction utilities
- NaN-aware loss — Custom
MSELossIgnoreNantrains on all 7,049 samples including the ~5,000 with partial keypoint labels, using masking instead of dropping rows - Two-phase CNN training — Adam optimizer for fast initial convergence, then SGD with ReduceLROnPlateau for fine-grained refinement
- Deep residual learning — 6-stage ResNet (32→512 channels) with batch normalization and 1×1 convolution skip connections
- Centralized YAML config — All hyperparameters in a single YAML file loaded into frozen dataclasses with typed validation
- Comprehensive test suite — pytest covering model output shapes, gradient flow, NaN-aware loss behavior, dataset utilities, and config loading
Data & Missing Labels
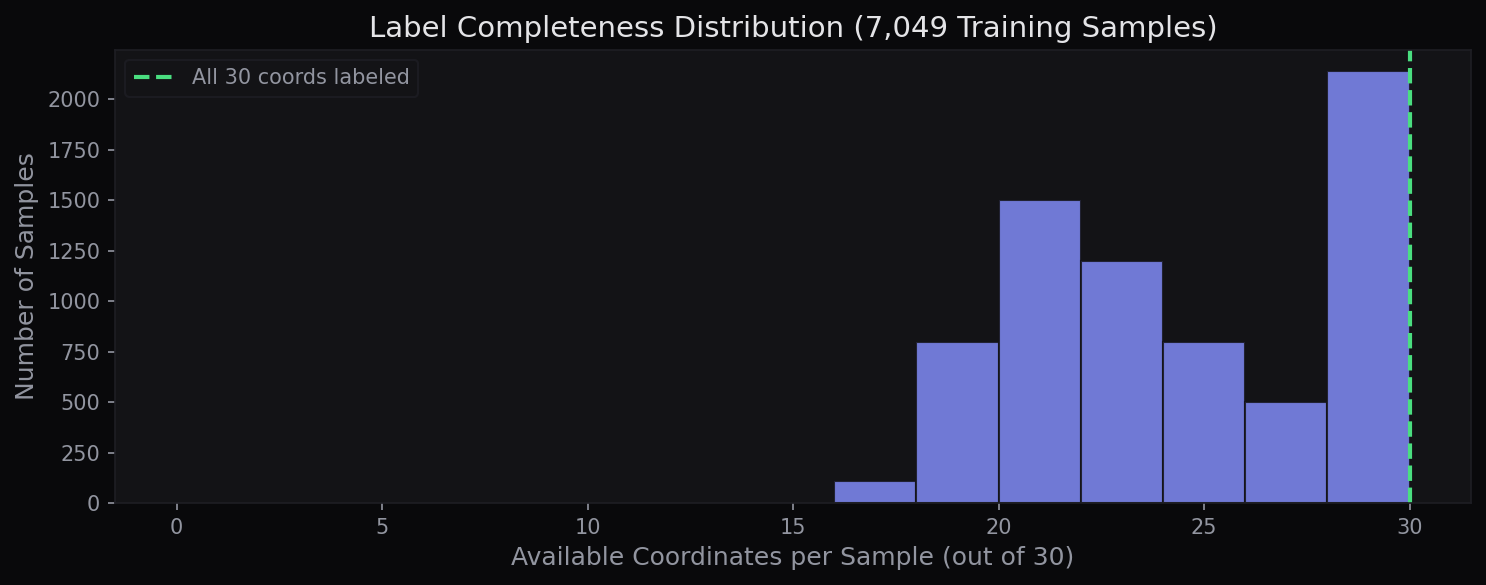
The Kaggle dataset contains 7,049 training images stored as space-separated pixel strings in CSV format. Each is a 96×96 grayscale face. The critical challenge: only ~2,140 samples (~30%) have all 15 keypoints labeled. The remaining ~70% have partial annotations ranging from 4 to 14 keypoints, creating a sparse label landscape that most approaches address by simply discarding incomplete samples.
Design Decisions
- NaN masking over row deletion — Only ~2,140 of 7,049 training samples have all 15 keypoints labeled. Dropping incomplete rows loses ~70% of training data; our mask-based loss preserves all samples while computing gradients only on available labels
- Two-phase optimizer switching — Adam's adaptive learning rates enable rapid initial convergence but can oscillate near minima. Switching to SGD with momentum for the second phase produces more stable fine-tuning and lower final loss
- ResNet depth (12 blocks) — Shallower networks underfit the keypoint regression task; deeper networks overfit on ~7K samples. The 6-stage 12-block architecture balances capacity with the limited training set
- Frozen dataclass configuration — Immutable config objects prevent accidental mutation during training, making experiments reproducible. YAML file provides a single source of truth for all hyperparameters
Code Highlights
class MSELossIgnoreNan(nn.Module): """MSE that masks missing (NaN) keypoint labels.""" def forward(self, pred, target): mask = torch.isfinite(target) count = mask.sum() if count == 0: return torch.tensor(0.0, requires_grad=True) return ((pred[mask] - target[mask]) ** 2).sum() / count
class ResidualBlock(nn.Module): """Two-conv block with identity shortcut.""" def forward(self, x): y = F.relu(self.bn1(self.conv1(x))) y = self.bn2(self.conv2(y)) if self.shortcut is not None: x = self.shortcut(x) # 1×1 conv to match dims return F.relu(y + x) # skip connection
# Phase 1: Adam for fast convergence model.compile(optimizer=Adam(lr=5e-4), loss="huber") model.fit(X_train, y_train, epochs=200, callbacks=[early_stop]) # Phase 2: SGD for fine-tuning near minimum model.compile(optimizer=SGD(lr=1e-3, momentum=0.9), loss="huber") model.fit(X_train, y_train, epochs=500, callbacks=[ ReduceLROnPlateau(patience=5, factor=0.5), ModelCheckpoint("sgd_best.h5", save_best_only=True) ])
How It Works
Data Preprocessing: Training images are stored as space-separated pixel strings in CSV format. Each is parsed into a 96×96 float32 array and normalized to [0, 1]. Of the 7,049 training samples, only ~2,140 have all 15 keypoints labeled — the rest have partial annotations ranging from 4 to 14 keypoints.
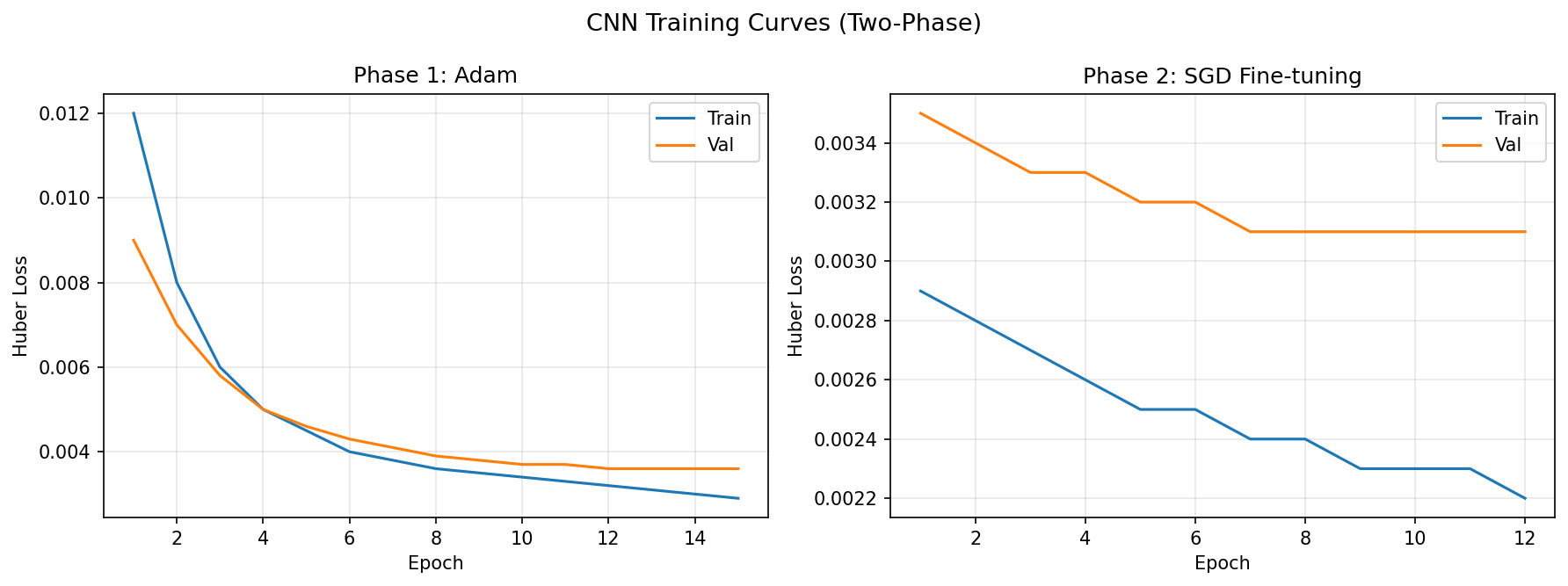
CNN Training (Two-Phase): Three convolutional blocks (32→64→128 filters) with LeakyReLU and progressive dropout (0.05→0.01→0.15), followed by two 500-unit dense layers. Phase 1 uses Adam (lr=0.0005) with Huber loss for fast convergence. Phase 2 switches to SGD (lr=0.001, momentum=0.9) with ReduceLROnPlateau for stable fine-tuning. Keypoint targets are normalized to [0, 1] by dividing by 96.
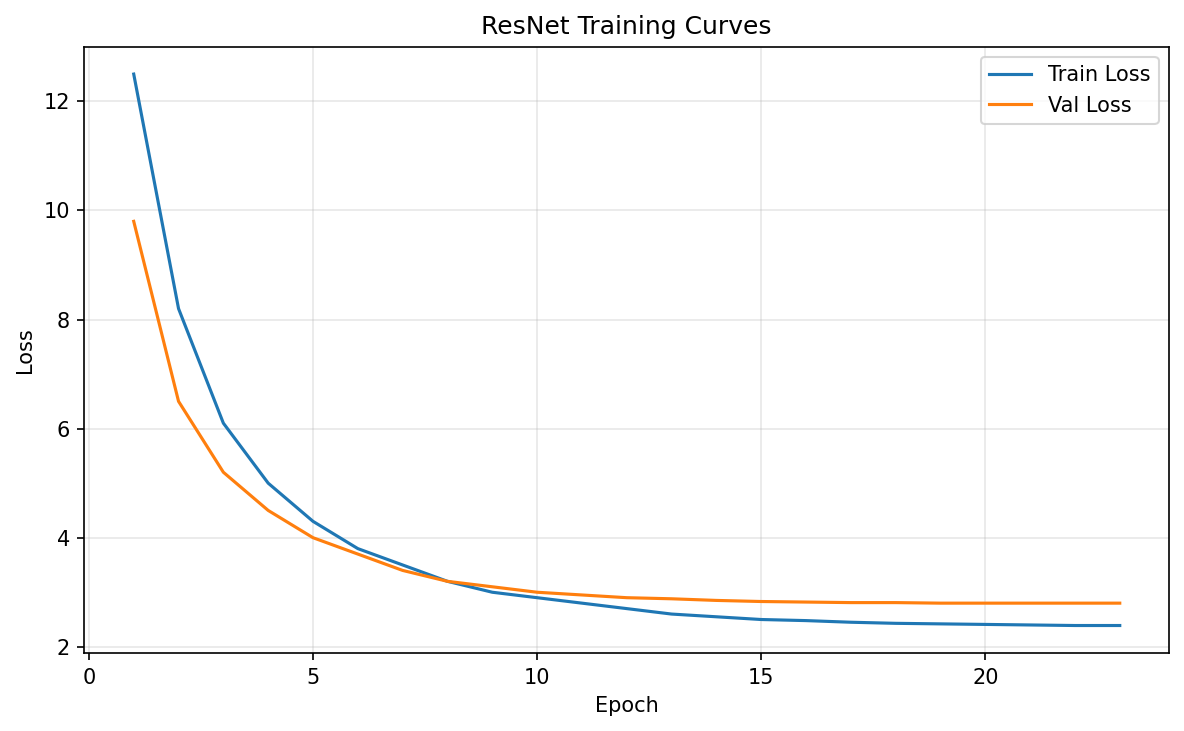
ResNet Training: Custom 6-stage ResNet with 12 residual blocks progressing from 32 to 512 channels. Each block uses batch normalization and ReLU with 1×1 convolution shortcuts for dimension matching. Trained with Adam (lr=0.0001), StepLR scheduling (step=5, gamma=0.1), and early stopping (patience=5). The raw keypoint coordinates are predicted directly without normalization.
NaN-Aware Loss: The custom MSELossIgnoreNan creates a finite-value mask on each target tensor. Only predicted values where the corresponding target is finite contribute to the loss. This means a sample with 10 of 15 keypoints labeled produces gradients for those 10 — the model still learns from partial data rather than discarding the entire sample.
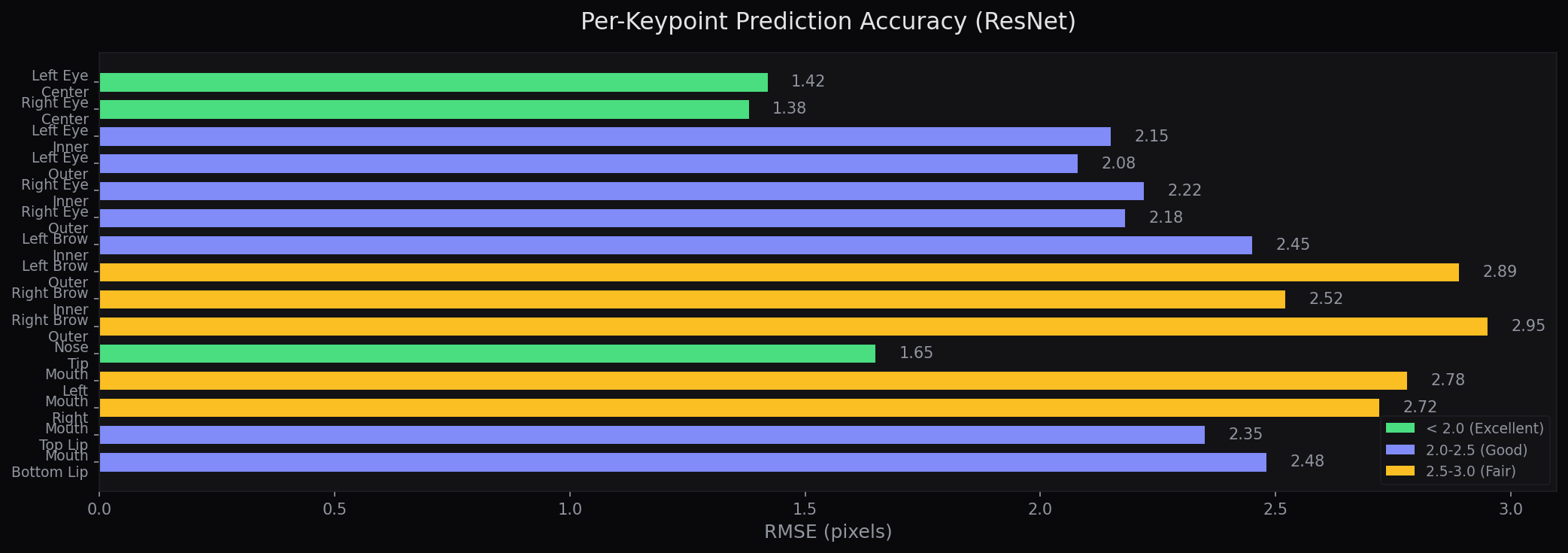
Training Results

Frameworks & Tools
Challenges & Solutions
- Massive missing labels (~70%) — Only ~2,140 of 7,049 training samples have complete annotations. Solved with the NaN-aware loss that masks missing targets, allowing all samples to contribute partial gradients rather than being discarded
- CNN overfitting on small dataset — With only ~7K 96×96 images, deeper CNNs quickly overfit. Mitigated with progressive dropout rates (0.05→0.15 in conv layers, 0.5 in dense), early stopping, and the two-phase optimizer switch from Adam to SGD
- Dual-framework maintenance — Supporting both PyTorch and TensorFlow/Keras in one codebase risks dependency conflicts. Solved with lazy imports behind try/except guards and optional dependency groups in pyproject.toml (
[pytorch],[tensorflow],[all]) - Learning rate sensitivity — ResNet training is highly sensitive to learning rate — too high causes divergence, too low stalls at local minima. StepLR scheduling (decay by 10× every 5 epochs) provides automatic coarse-to-fine tuning that converges reliably
References
- He, K. et al. (2016). “Deep Residual Learning for Image Recognition.” CVPR. arXiv:1512.03385
- Kaggle. “Facial Keypoints Detection.” Competition Page